Selected Publications
 |
Conditional Diffusion Distillation A novel conditional distillation method to distill an unconditional diffusion model into a conditional one for faster sampling while maintaining high image quality. |
 |
MULLER: Multilayer Laplacian Resizer for Vision Super lightweight resizer w/ literally a handful of trainable parameters. Plugged into training pipelines, it significantly boosts the performance of the underlying vision task at ~no cost. |
V2V4Real: A large-scale real-world dataset for Vehicle-to-Vehicle Cooperative Perception
Runsheng Xu, Xin Xia, Jinlong Li, Hanzhao Li, Shuo Zhang, Zhengzhong Tu, Zonglin Meng, Hao Xiang, Xiaoyu Dong, Rui Song, Hongkai Yu, Bolei Zhou, Jiaqi Ma
Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023, Vancouver
[Arxiv]
[Paper (PDF)]
[Supp]
[Project page]
[Code]
[Video]
[BibTex]
@inproceedings{xu2023v2v4real,
title={V2v4real: A real-world large-scale dataset for vehicle-to-vehicle cooperative perception},
author={Xu, Runsheng and Xia, Xin and Li, Jinlong and Li, Hanzhao and Zhang, Shuo and Tu, Zhengzhong and Meng, Zonglin and Xiang, Hao and Dong, Xiaoyu and Song, Rui and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={13712--13722},
year={2023}
}
CVPR 2023 Highlight (2.5% of 9155 submissions)
V2V4Real is the first large-scale real-world dataset for Vehicle-to-Vehicle (V2V) cooperative perception in autonomous driving.
 |
Pik-Fix: Restoring and Colorizing Old Photos A novel learning framework that is able to both repair and colorize old, degraded pictures with a first-of-a-kind paired real old photos dataset. |
 |
CoBEVT: Cooperative bird's eye view semantic segmentation with sparse transformers A new cooperative BEV map segmentation transformer that contains 3D fused axial attention (FAX) module with linear complexity, and is generalizable to other tasks. |
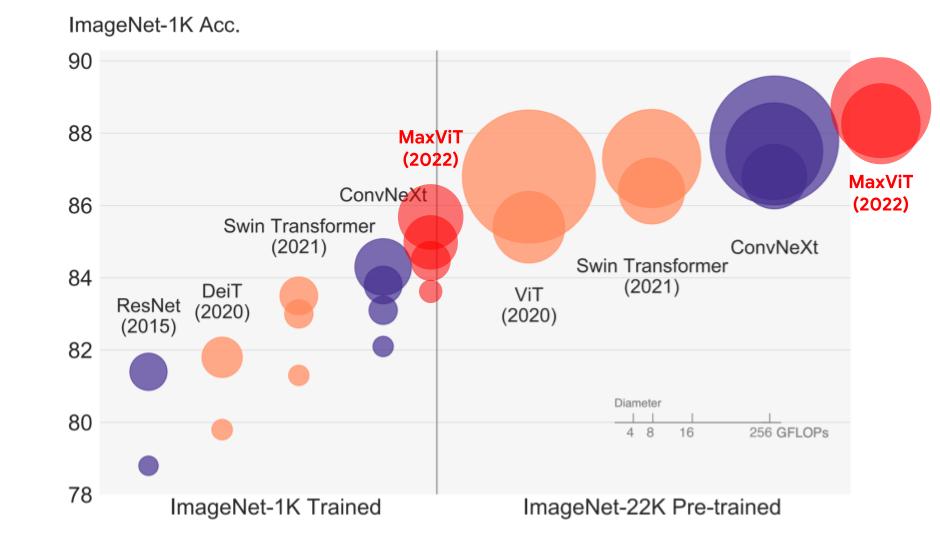 |
MaxViT: Multi-Axis Vision Transformer Highlighted on-top in Jeff Dean's 2022 Annual Google Research Blog; Selected as top-3 papers of the year in Ahead of AI #4: A Big Year for AI; Retweeted by the Yann Lecun: link A new scalable local-global attention mechanism called multi-axis attention, stacked into a family of hierarchical vision transformer dubbed MaxViT, that attains 86.5% ImageNet-1K top-1 accuracy without extra data and 88.7% top-1 accuracy with ImageNet-21K pre-training. |
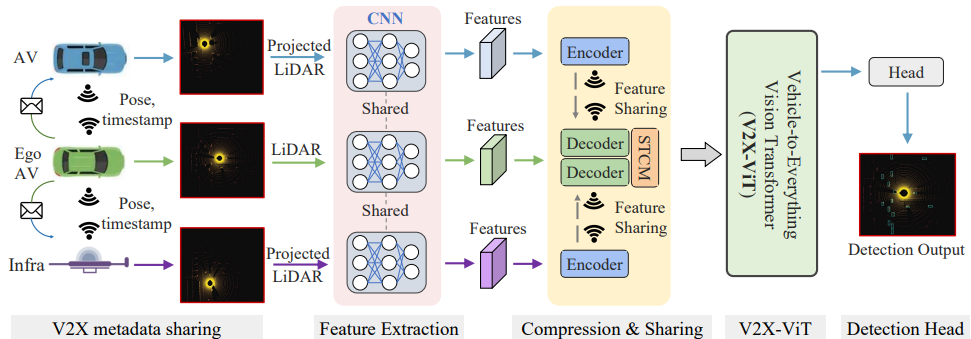 |
V2X-ViT: Vehicle-to-Everything Cooperative Perception with Vision Transformer A holistic vision Transformer that uses heterogeneous multi-agent attention and multi-scale window attention to handle common V2X challenges, including latency, pose errors, etc. |
 |
MAXIM: Multi-Axis MLP for Image Processing Best paper nomination award (0.4% of 8161 submissions) An MLP-based architecture that can serve as a foundation model for image processing tasks, achieving SoTA performance on >10 benchmarks across broad image processing tasks, including denoising, deblurring, deraining, dehazing, and enhancement. |
 |
Subjective Quality Assessment of User-Generated Content Gaming Videos A new UGC gaming video VQA resource, named LIVE-YT-Gaming database, composed of 600 UGC gaming videos and 18,600 subjective quality ratings collected from an online subjective study |
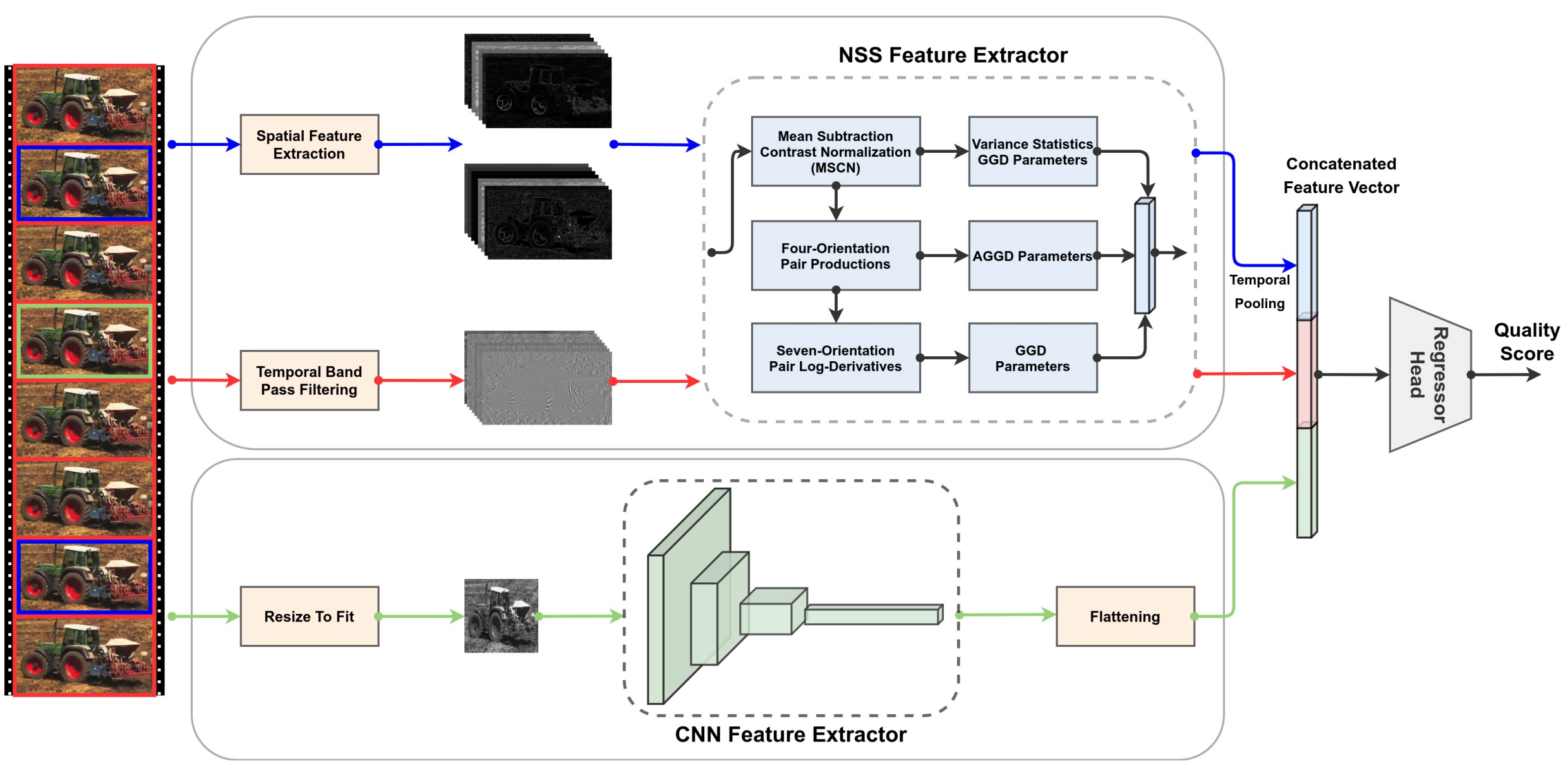 |
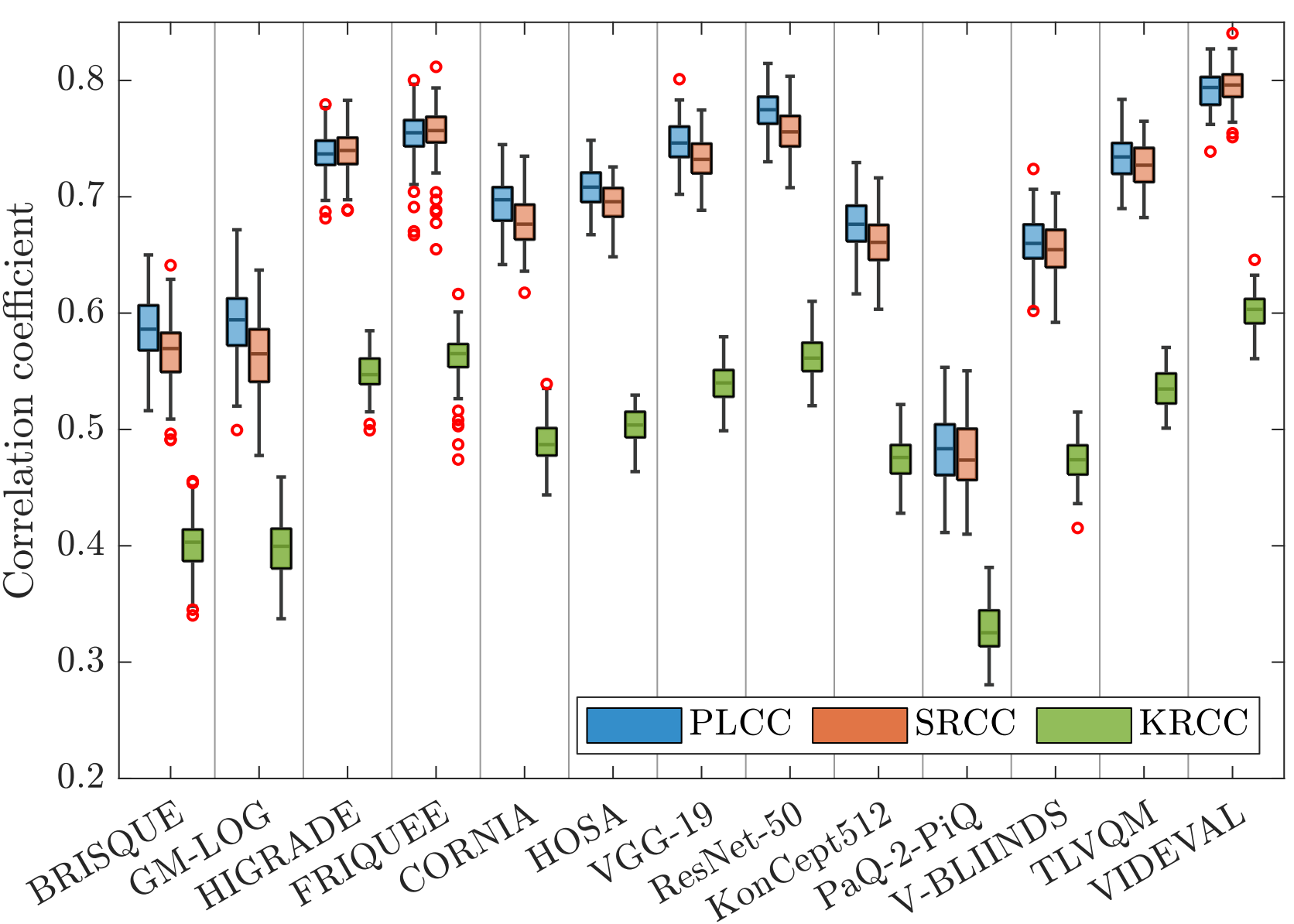
RAPIQUE: Rapid and Accurate Video Quality Prediction of User Generated Content Highlighted in OJSP 2022 newsletter A hybrid blind video quality assessment model for user-generated content, that performs comparably to SoTA models but with orders-of-magnitude faster runtime. |
 |
UGC-VQA: Benchmarking Blind Video Quality Assessment for User Generated Content The most cited paper published after 2021 in the video quality assessment field For the first time, we defined and coined the 'UGC-VQA problem', providing comprehensive benchmark, and built a new compact-feature model with SoTA performance. |
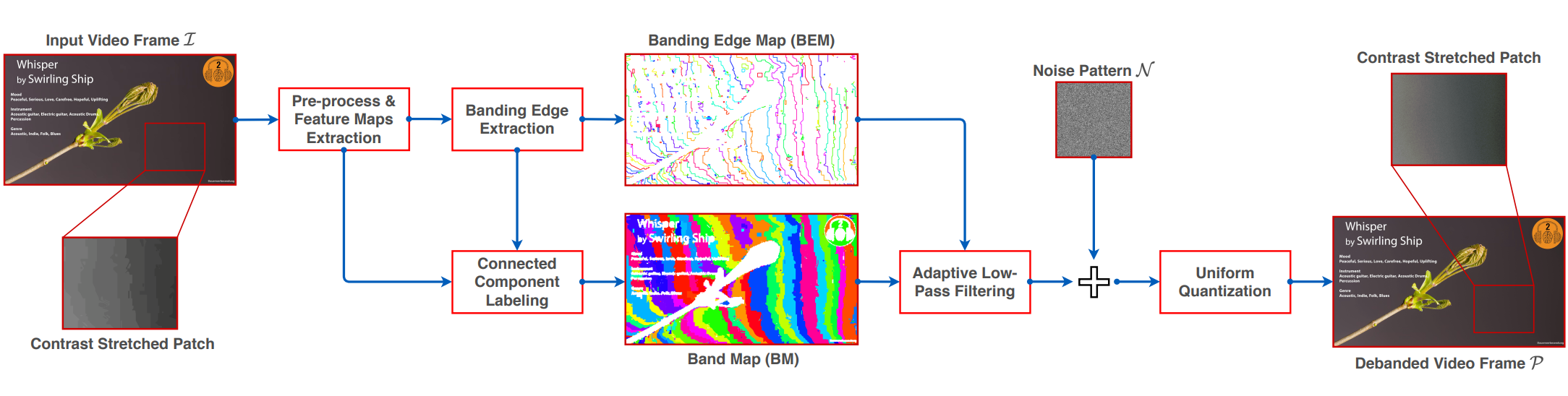 |
Adaptive Debanding Filter A debanding filter that is able to adaptively smooth banded regions while preserving image edges and details, yielding perceptually pleasing results. |
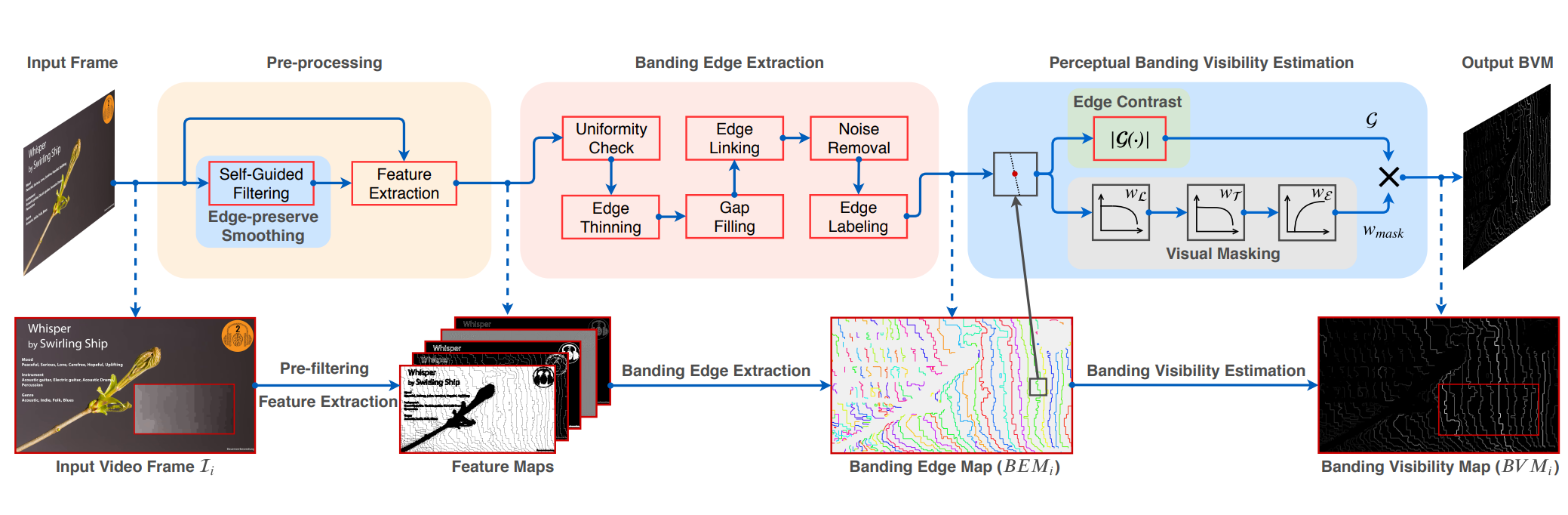 |
BBAND index: A no-reference banding artifact predictor A new distortion-specific no-reference video quality model for predicting banding artifacts in compressed videos. |